Описание операций
Работа с MLFlow
Общие сведения
Управление экспериментами и жизненным циклом моделей реализовано с помощью open source решения MLflow.
С помощью MLflow Пользователь системы имеет возможность при каждом запуске кода сохранять и отслеживать следующие данные:
- Параметры модели (это значения параметров, при которых данная модель обучалась, например, для решающего дерева максимальная глубина дерева является параметром);
- Метрики модели (это показатели качества уже обученной модели, например, ROC-AUC);
- Теги эксперимента/модели - информация (например: имя разработчика, ссылка на используемую витрину) об особенности конкретного запуска/модели;
- Имя файла, который вызывает запуск кода;
- Версию кода;
- Различные артефакты, например изображения, файлы моделей, файлы в формате .md (для описания задачи и модели, решающей ее);
- Модель (сохраняется в качестве артефакта) - папка model c файлом модели в формате .pkl.
После завершения выполнения кода Пользователь имеет возможность посмотреть собранные данные с помощью веб-интерфейса MLFlow.
Просмотр экспериментов в MLFlow
Для просмотра реестра экспериментов проекта необходимо перейти во вкладку Experiments на странице проекта в модуле A2P, далее развернуть запуски эксперимента с интересующими метриками нажатием на "+" (см. рисунок ниже).
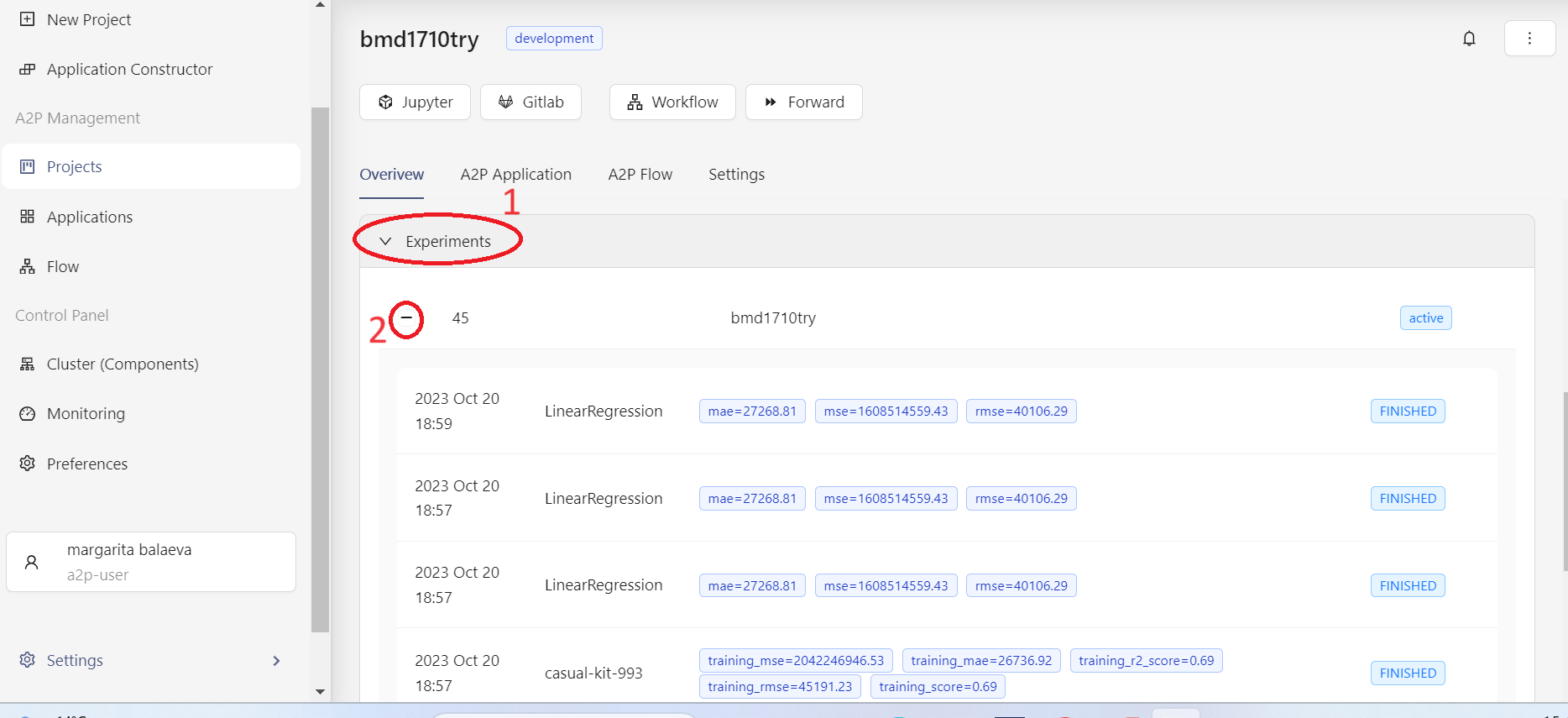
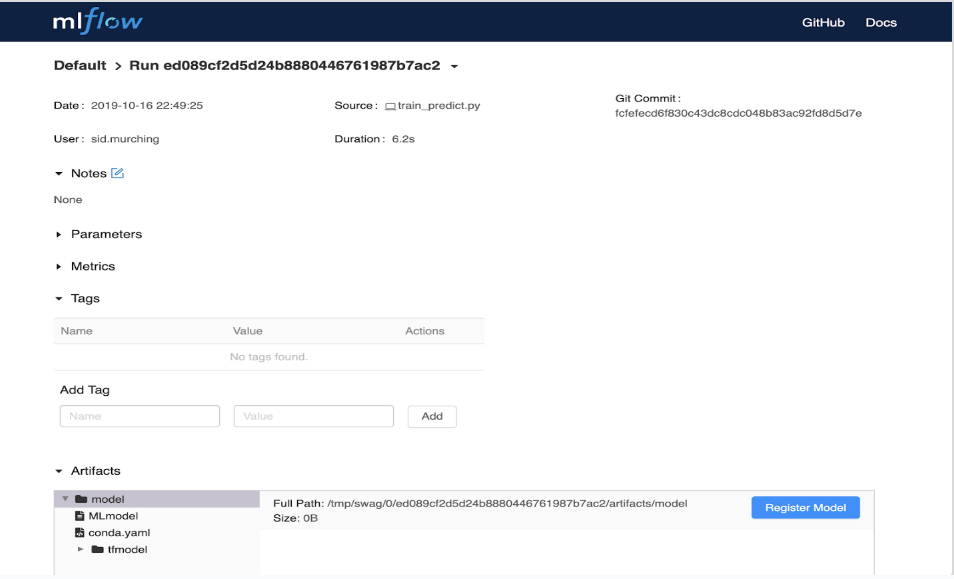
Для перехода на страницу с подробной информацией о конкретном запуске (run) необходимо кликнуть на запись соответвующего запуска.
Логирование эксперимента
Рассмотрим логирование на примере обучения и предсказания простейшей модели решающего дерева, код которого представлен ниже:
1 import mlflow
2 import numpy as np
3 from sklearn.tree import DecisionTreeRegressor
4 from sklearn.model_selection import train_test_split
5 from sklearn.linear_model import LinearRegression
6 from sklearn.metrics import *
7
8 X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.5, random_state=5)
9
10 experiment_name = 'Test_experiment'
11 mlflow.set_experiment(f"{experiment_name}")
12 mlflow.set_experiment_tag("project", "")
13 for i, max_depth in enumerate([5, 10, 30], start=1):
14 with mlflow.start_run(run_name=f'DecisionTree_run_{i}') as run:
15 dtr = DecisionTreeRegressor(max_depth = max_depth,
16 min_samples_leaf = 5,
17 ccp_alpha = 0.00018)
18
19 dtr = dtr.fit(X_train, y_train)
20
21 y_pred = dtr.predict(X_test)
22 mae = mean_absolute_error(y_test, y_pred)
23 mse = mean_squared_error(y_test, y_pred)
24 rmse = np.sqrt(mean_squared_error(y_test, y_pred))
25
26 mlflow.log_metric('mae', mae)
27 mlflow.log_metric('mse', mse)
28 mlflow.log_metric('rmse', rmse)
29 mlflow.log_param('model', 'DecTree')
30 mlflow.log_param('max_depth', max_depth)
На строке 8 происходит разделение датасетов с фичами X и таргетом Y на данные для тренировки и валидации, следует обратить внимание, что предварительно X и Y необходимо загрузить отдельно.
На строках 10–11 задается имя эксперимента, под которым он будет отображаться в интерфейсе MLflow на вкладке Experiments. В случае, если ранее в Системе такого эксперимента ранее не было, то на экран будет выведено уведомление о создании эксперимента с данным именем. Рекомендуется создавать отдельный эксперимент для каждой модели.
На строке 12 задается тег экмперимента.
На строках 13-30 задан цикл, который проходит одновременно по индексу i от 1 до 3 и по параметру max_depth (максимальная глубина решающего дерева) по значениям 5, 10, 30. Внутри каждого цикла на строке 14 с помощью контекстного менеджера with выполняется запуск рана (run). Под раном подразумевается участок кода, имеющий отношение к ML-модели. Имя рана в данном случае будет DecisionTree_run_i, где i принимает значения 1, 2, 3.
На строке 15 обозначается создание объекта решающего дерева, которому в качестве параметра максимальной глубины передается значение max_depth, равное 5, 10 и 30.
На 19 строке происходит обучение дерева.
На 21 строке выполняется предсказание (скоринг).
На строках 22–24 происходит расчет метрик обученной модели.
На строках 26–28 происходит логирование рассчитанных выше метрик модели, название метрики указывается первым аргументом как строка, а значение метрики указывается вторым аргументом.
На строках 29–30 выполняется логирование параметров модели, где первым параметром передается строка, задающая имя параметра, а вторым - значение данного параметра.
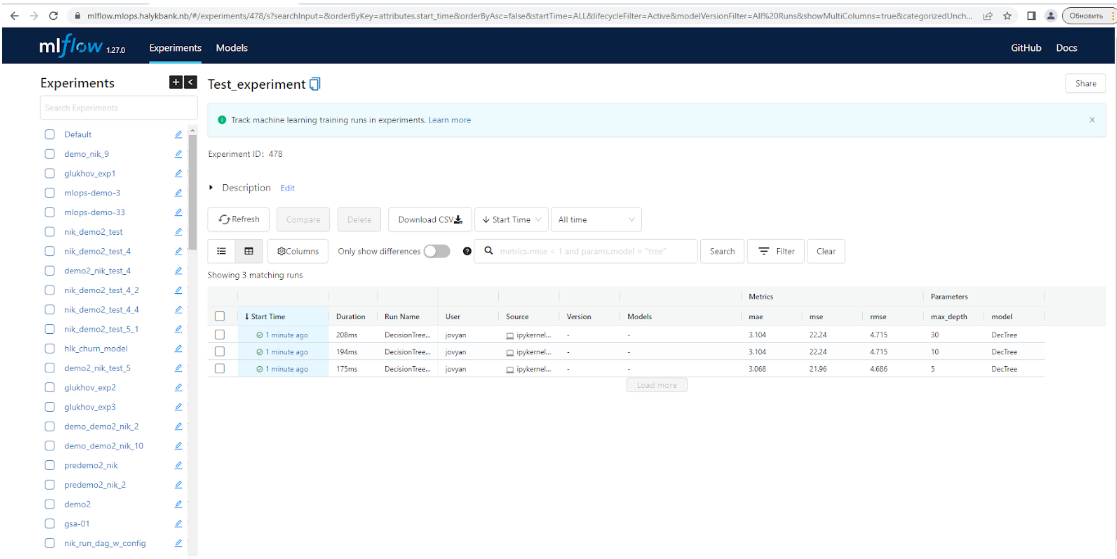
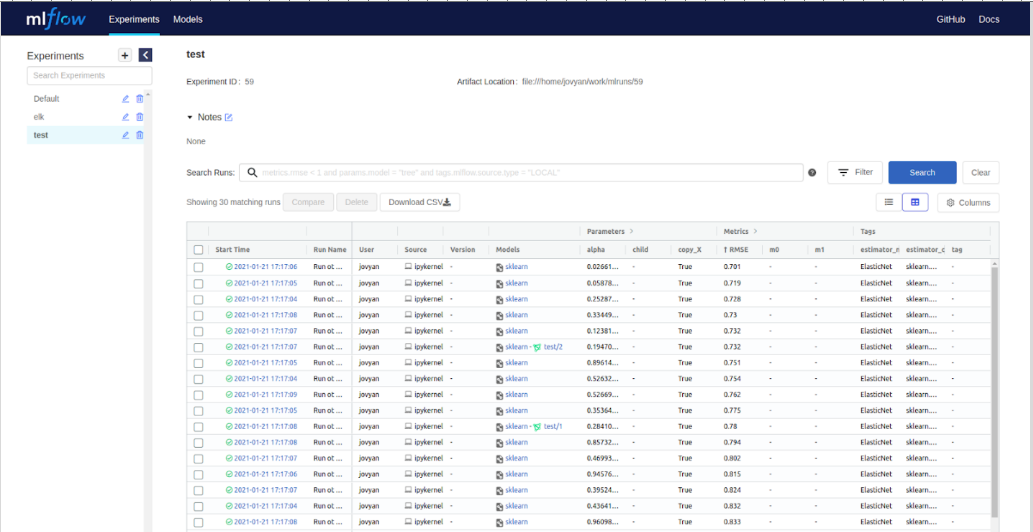
Таким образом, после запуска данного кода в реестре экспериментов MLflow будет создан эксперимент с именем Test_experiment, который содержит три запуска (три рана) с названиями (см. рис. ниже). При этом будут указаны метрики mae, mse, rmse для трех вариантов решающего дерева, отличающихся параметром максимальной глубины 5, 10 и 30.
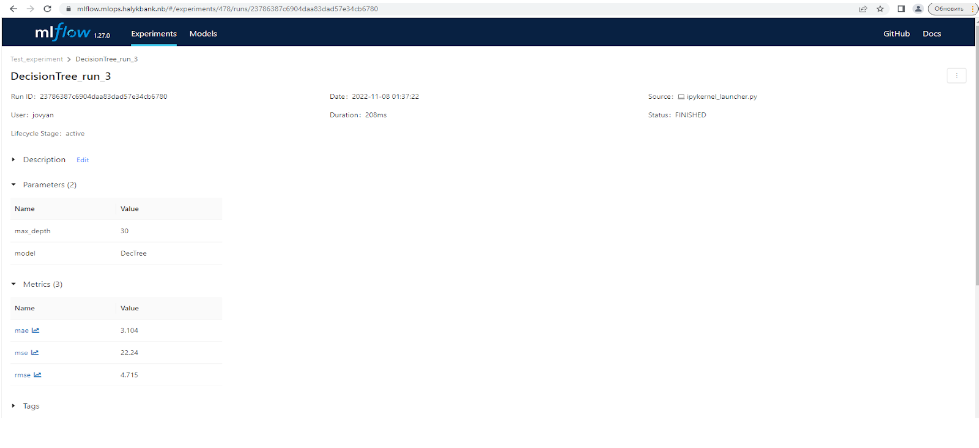
Если открыть форму запуска «run» (“провалиться” внутрь) в какой-либо запуск (ран), то на экране будут отображены логированные атрибуты модели, в данном примере это два параметра и три метрики (см. рис. ниже).
Также бывает полезным логировать тэги и саму модель, более подробно про возможности логирования можно прочитать в документации Mlflow https://www.mlflow.org/docs/latest/index.html.
Поиск запуска по параметрам
В случае, когда эксперимент содержит большое количество runs, то оказывается удобным воспользоваться фильтрацией отображаемые runs по параметру. Рассмотрим пример, перейдя на основную страницу MLflow.
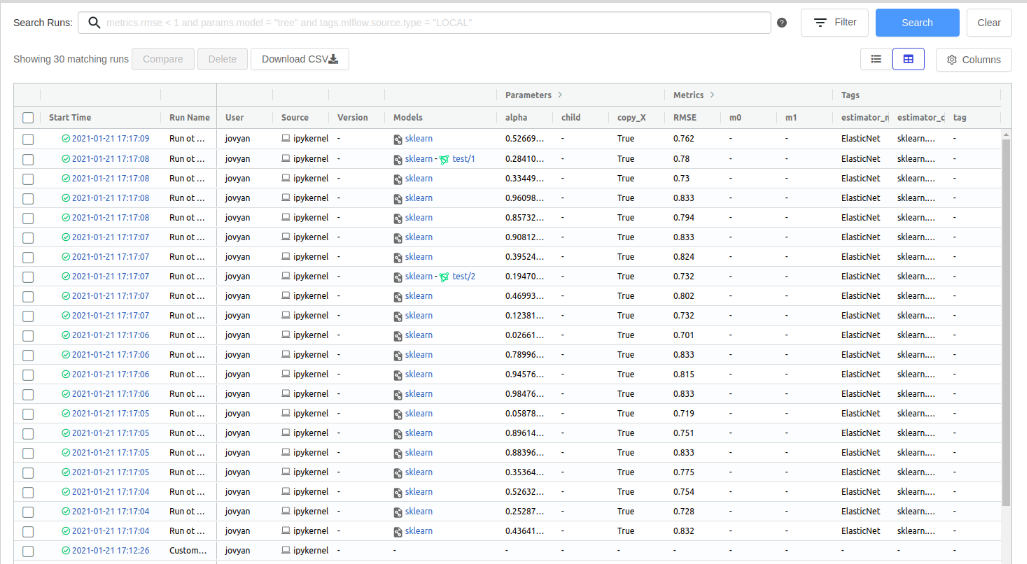
На странице списка запусков (run) в поле поиска ввести строку с параметрами, например: metrics.RMSE >= 0.8
И нажать на кнопку “Search” для поиска запусков, но на экране отобразятся только запуски, удовлетворяющие данному критерию.
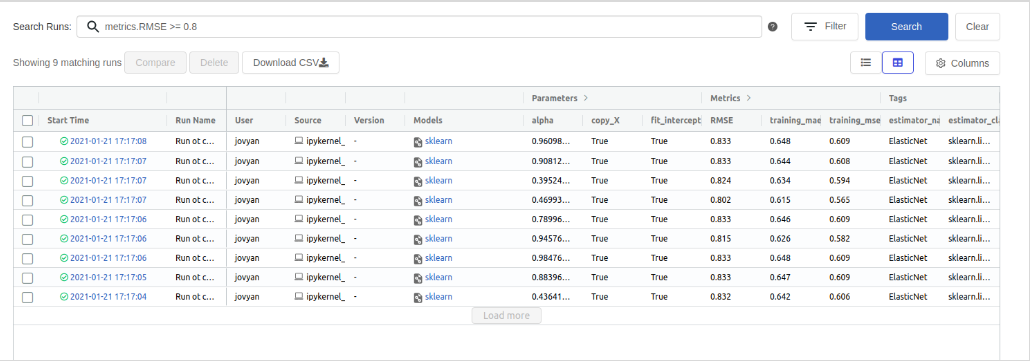
Сортировка по значению в столбце
Запуски можно отсортировать по значениям в порядке убывания (возрастания) по одному столбцу, нажав на соответствующий столбец.
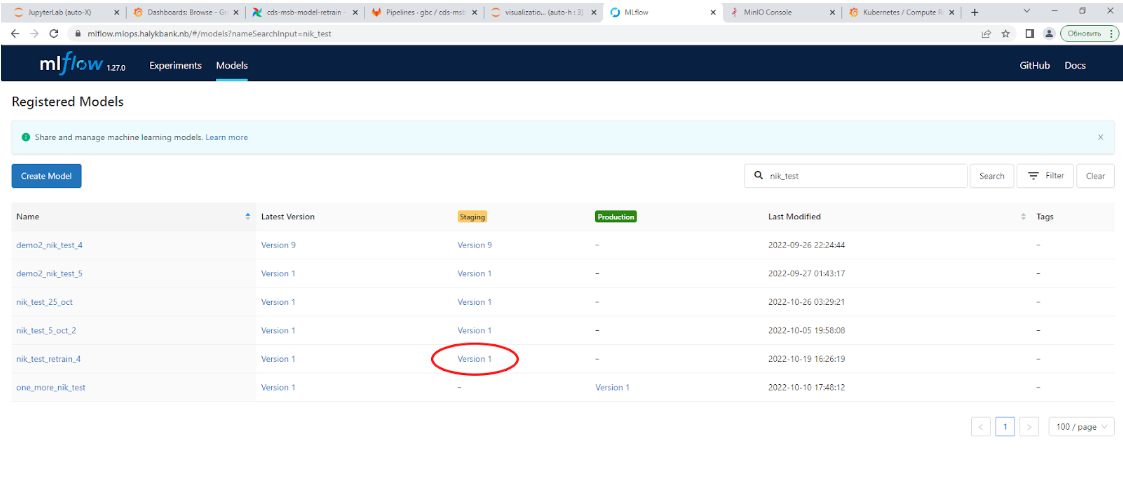
Удаление модели и эксперимента
Для удаления модели из реестра моделей MLflow сперва требуется перевести модель в стадию “Archived”. Для этого нужно в реестре моделей выбрать версию, находящуюся на самой высокой стадии, в данном примере на рисунке ниже это стадия “Staging”.
Для перевода в стадию “Archived” нужно нажать на поле “Stage”, выбрать “Transition to Archived”. После этого в меню под цифрой 2 на рисунке ниже появиться возможность удалить (Delete), после нажатия на Delete, появиться меню с предупреждением, что действие безвозвратно удалит версию модели со всеми артефактами, нужно ввести подтверждение.
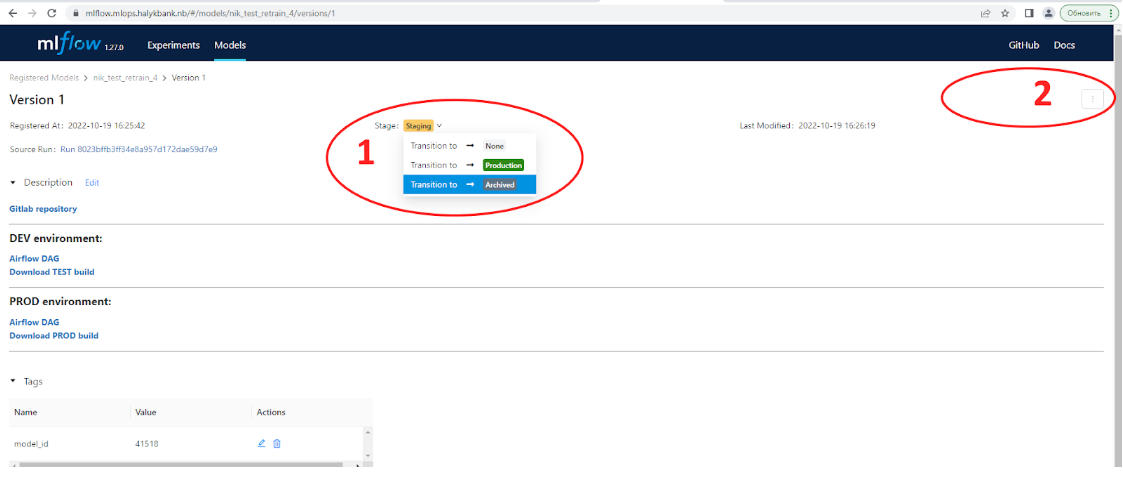
После того как все версии модели удалены, тогда при нажатии на название модели в реестре, будет открыто окно, подобное тому, как на рисунке выше, в этом окне нужно выбрать значок с 3 точками (цифра 2 на рисунке) и еще раз прожать удаление модели. После этого модель будет удалена из реестра моделей.
Полное удаления эксперимента из таблицы “Experiments” в силу особенностей архитектуры MLflow проблематично, однако для нормальной работы на Платформе достаточно удалить все run's внутри данного эксперимента. Рассмотрим процесс на рисунке ниже.
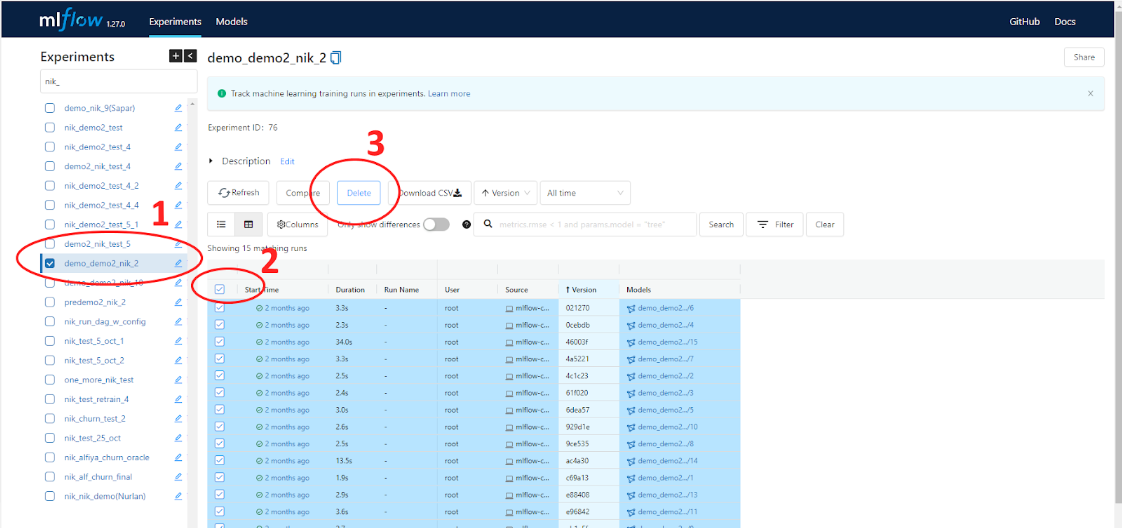
Сначала выбираем имя эксперимента (цифра 1), все запуски которого требуется удалить. Далее выбираем все или некоторые запуски (цифра 2), далее нажимаем кнопку “Delete” (цифра 3), после этого еще раз подтверждаем удаление. Теперь выбранные запуски будут удалены.