Описание операций
Работа с Jupyter
Авторизация в системе
В адресной строке браузера необходимо ввести ссылку, полученную от Администратора Системы для доступа в модуль A2P.
При первоначальном входе в Систему Пользователю будет предоставлено окно авторизации. Для успешного входа в связанные между собой приложения используется инструмент «Keycloak», он позволяет провести аутентификацию пользователя единожды и получить доступ к другим приложениям без последующего входа в каждом из них, кроме GitLab.
Примечание: настройки групп пользователей уточняйте у Администратора Системы
Создание проекта в A2P
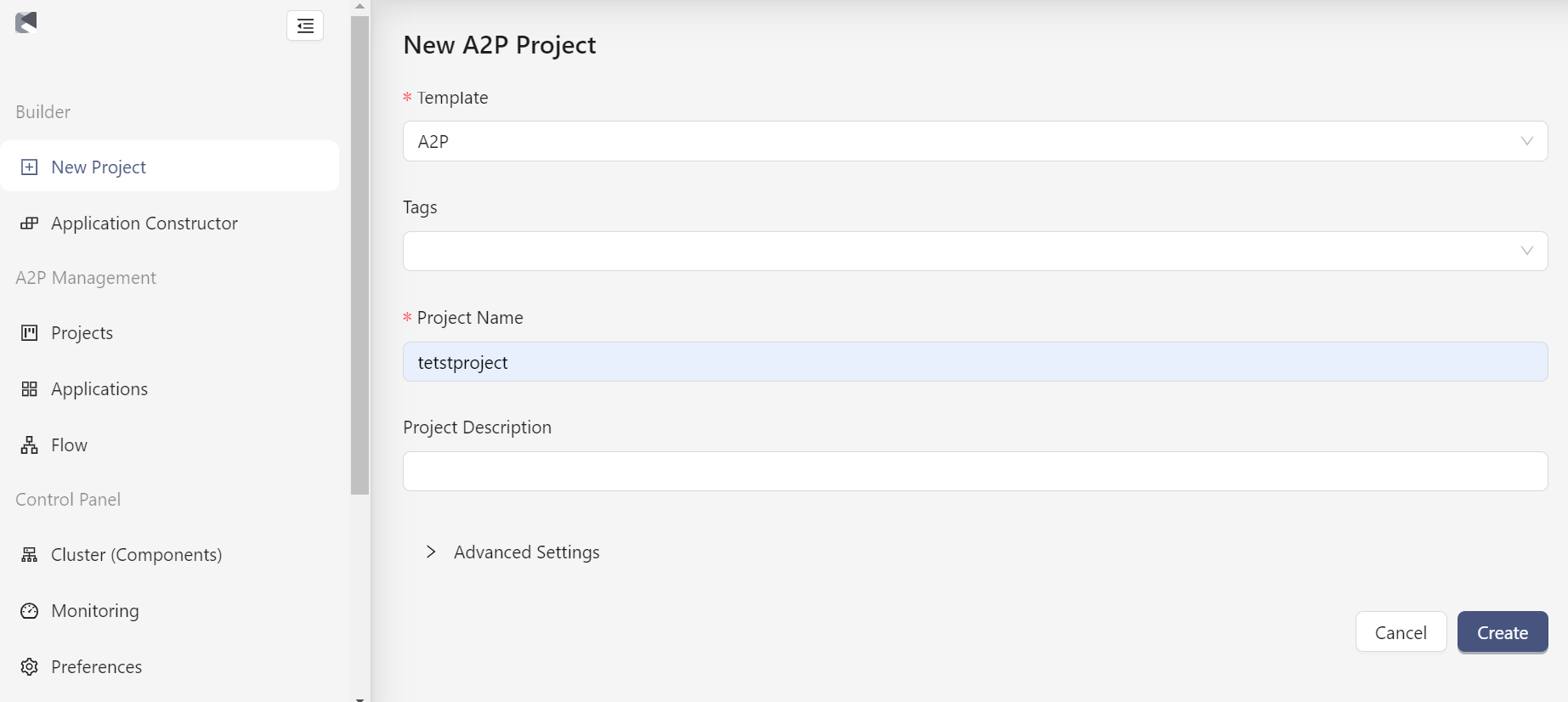
Для создания проекта необходимо нажать бна "New Project", затем задать параметры проекта (см. рисунок ниже):
- Выбрать шаблон (Template);
- Указать тэги (Tags);
- Ввести имя проекта (Project Name);
- Добавить описание проекта при необходимости (Priject Description).
Инициализация Jupyter контейнера
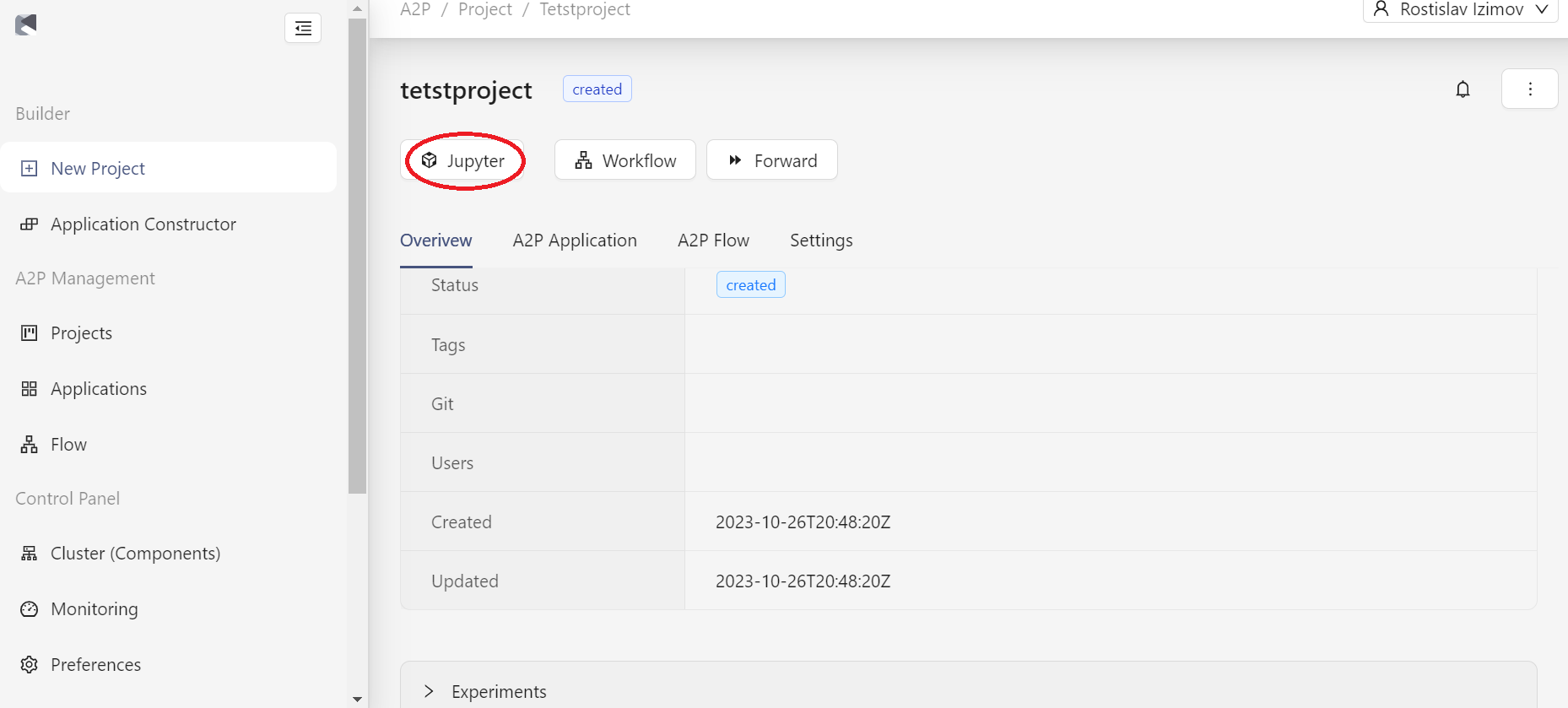
После создания проекта в модуле A2P на странице с информацией о новом проекта необходимо перейти в Jupyter (см. рисунок ниже).
Выбор и запуск JupyterLab сервера
В открывшемся окне необходимо выбрать желаемый стек и вычислительные параметры Jupyter сервера.
В системе предусмотрен выбор базового образа. Если разрабатываемая модель машинного обучения не подразумевает работы с нейронными сетями, то следует использовать первый более “легкий” образ, в противном случае выбирайте второй - более “тяжелый”.
Полный список предустановленных в каждый образ библиотек можно узнать у Администратора. Следует помнить, что если Пользователю дополнительно нужны новые библиотеки, то он может их установить с помощью терминала и команды pip install.
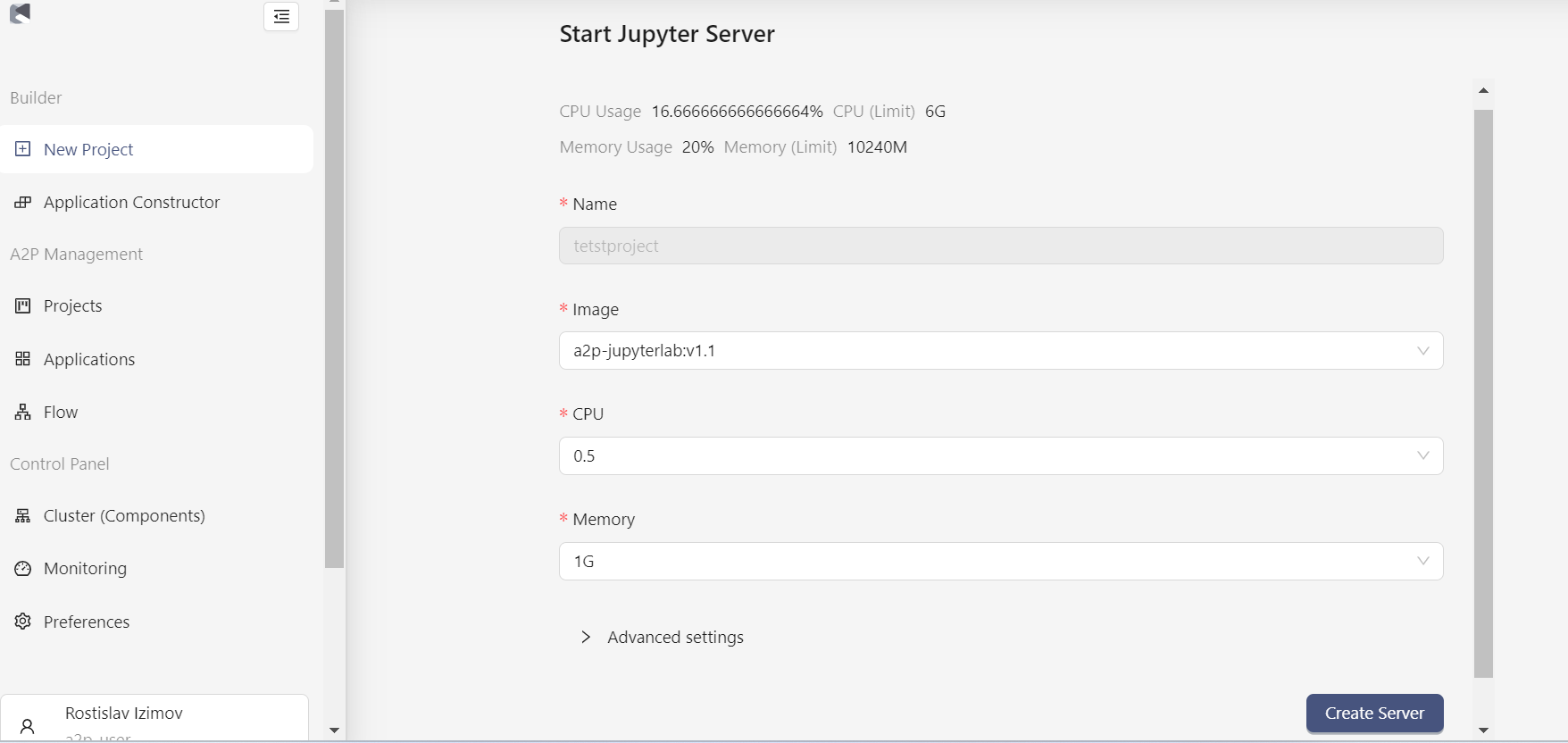
Стек (преднастроенное пользовательское окружение) можно выбрать из выпадающего списка. Аналогичным образом задаются другие параметры: количество ядер и размер оперативной памяти сервера.
После того как параметры выбраны, нажмите на кнопку “Create Server”. Это запустит процесс создания сервера Jupyter Lab.
После создания сервера происходит автоматическое перенаправление на основной экран JupyterLab.
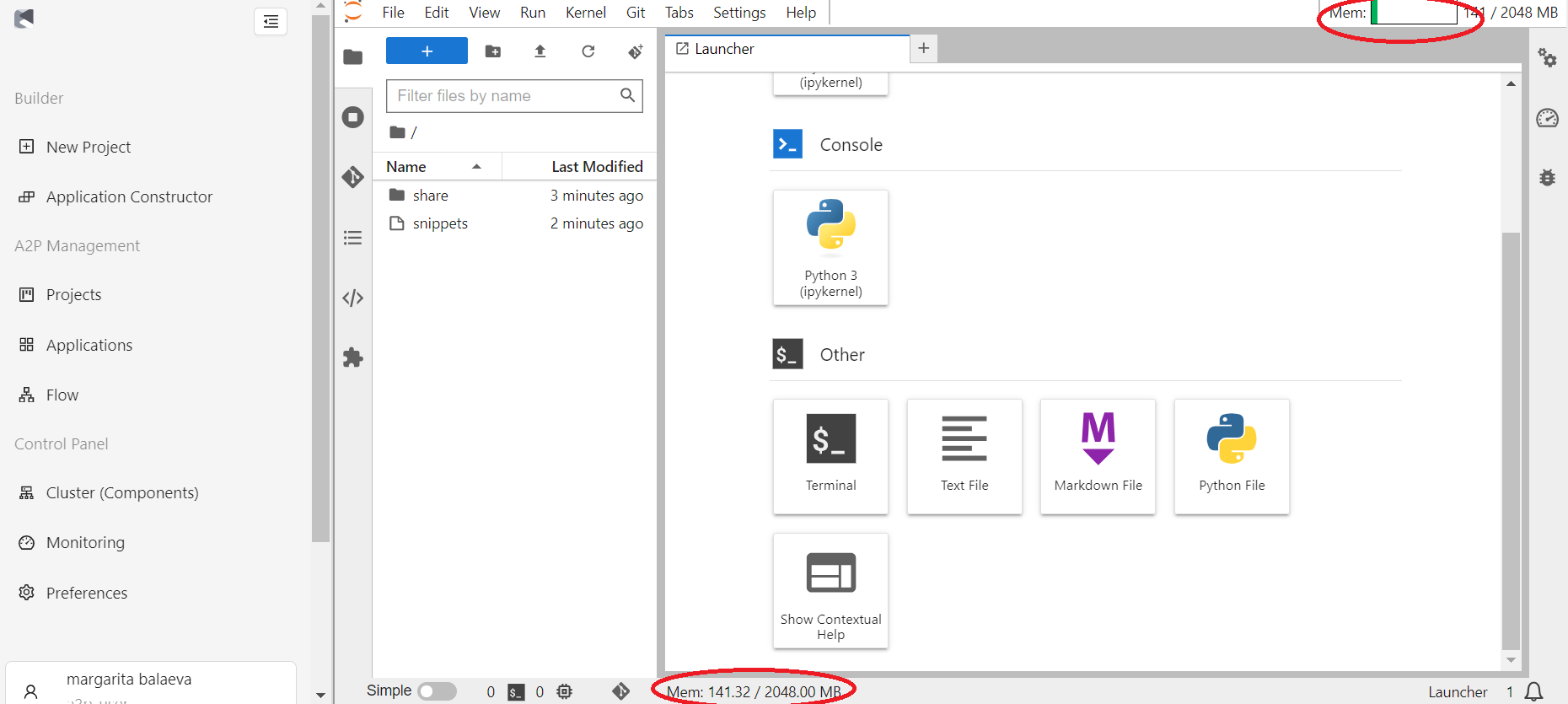
Примечание: время жизни сервера неограниченно, поэтому после завершения работы требуется обязательно завершить сессию, во избежание частичной потери информации. Для завершения сессии перейдите в меню “File”, выберите “Hub Contol Panel”, в открывшемся окне выберите “Stop My Server”. В ряде случаев возможна принудительная остановка сервера Администратором после определенного времени бездействия Пользователя.
Структура проекта для batch модели
Проект представляет собой способ организации и описания кода, который принят в рамках рассматриваемой Системы. Единый подход к организации кода облегчает совместную работу нескольких специалистов, а также открывает возможности использования средств автоматизации.
Проект представляет собой структуру файлов и директорий, которая также является локальной версией репозитория git. В директории проекта могут находиться различные файлы, включая файлы блокнотов, скрипты, файлы конфигурации.
Структура проекта для batch модели:
├── README.md - Файл с описанием бизнес назначения модели
├── data - Директория для хранения датасетов
│ ├── processed
│ └── raw
├── gitlab-ci - Директория, содержащая конфигурационные файлы
│ ├── Dockerfile - докерфайл для продуктивизации модели
│ ├── dag-batch.py - DAG файл для применения модели в Airflow
│ ├── dag-retrain.py - DAG файл для вызова переобучения в Airflow
│ ├── mlflow-create-model.py - Python скрипт для работы с MLflow
│ ├── mlflow-stage-model.py - Python скрипт для работы с MLflow
│ └── start.sh - файл для bash, запускаемый в контейнере
├── logging - Директория для логирования работы модели или иных логов
├── media - Директория для медиа файлов, например картинок .png.
├── models
│ ├── main.py - Python скрипт для скоринга моделью
│ └── retrain.py - Python скрипт для переобучения модели
├── notebooks - Директория для Jupyter ноутбуков
├── online - Директория с файлами для онлайн модели
│ ├── Dockerfile
│ ├── deployment.yaml
│ ├── ingress.yaml
│ ├── requirements.txt
│ ├── service.yaml
│ └── src
│ ├── api.py
│ ├── html
│ │ └── index.html
│ ├── pkl
│ ├── scheme_api
│ │ └── scheme.py
│ └── solver
│ └── main.py
├── pkl - Директория для хранения pkl файлов
└── requirements.txt Файл с необходимыми библиотеками
Примечание: oписание используемых моделью библиотек должно находиться в файле requirements.txt, который располагается в основной папке проекта. Для создания файла можно выполнить в терминале (см. раздел Работа с терминалом) команду pip freeze > requirements.txt, при этом нужно убедиться, что полученный файл оказался в корневой директории проекта. Данный файл можно оставить пустым, если Пользователь не устанавливал никаких дополнительных библиотек к уже существующим в данном базовом образе. Более подробно про дополнительные библиотеки смотрите в разделе “Установка дополнительных библиотек”.
Структура проекта для online модели
Структура проекта для online модели:
├── README.md - Файл с описанием бизнес назначения модели
├── chart - Директория для файлов helm-chart
│ ├── Chart.yaml
│ ├── NOTES.txt
│ ├── templates
│ │ ├── _helpers.tpl
│ │ ├── deployment.yaml
│ │ ├── hpa.yaml
│ │ ├── ingress.yaml
│ │ ├── service.yaml
│ │ └── serviceaccount.yaml
│ └── values.yaml
├── gitlab-ci - Директория, содержащая конфигурационные файлы
│ ├── Online-Dockerfile - докерфайл для продуктивизации online модели
│ ├── Online-start.sh
│ ├── Retrain-Dockerfile - докерфайл для продуктивизации retrain модели
│ ├── Retrain-start.sh
│ ├── dag-retrain.py - DAG файл для вызова переобучения в Airflow
│ ├── mlflow-create-model.py - Python скрипт для работы с MLflow
│ └── mlflow-stage-model.py - Python скрипт для работы с MLflow
├── notebooks
├── requirements.txt - Файл с необходимыми библиотеками
├── sample-model - Директория с примером обучения шаблонной online модели
│ ├── online_notebook.ipynb
│ └── sample.json - Пример входного вектора для шаблонной online модели
├── sonar-project.properties - Файл с параметрами Sonarqube
└── src
├── api.py - Файл с api веб-сервиса на fastapi
├── html
│ └── index.html - Файл с html страницей для шаблонной online модели
├── pkl - Директория для сохранения сериализованных файлов модели
├── scheme_api
│ └── scheme.py
└── solver
├── main.py - Скрипт для применения online модели
└── retrain.py - Скрипт для переобучения online модели
Описание файла main.py
Файл предназначен для скоринга обученной ранее моделью. После создания проекта файл main.py создается по шаблону и имеет вид, представленный ниже:
1 import os
2 import pandas as pd
3 import pickle
4
5 print("TARGET_DATE=", os.environ.get('TARGET_DATE'))
6
7 target_date = os.environ.get('TARGET_DATE', None)
8
9 if target_date is None:
10 raise RuntimeError("Error! Не передана дата скоринга!")
11
12 date_for_prediction = target_date
13
14 with open("./pkl/model.pkl","rb") as f:
15 p = pickle.load(f)
16 print(p)
17 print("good")
На 5 строке происходит вывод на экран переменной окружения TARGET_DATE, которая считывается в скрипт main.py с помощью команды os.environ.get. Данная переменная далее должна использоваться как дата для скоринга моделью. Если данная переменная окружения не обнаружена, то работа скрипта будет прервана исключением на строке 10.
Далее на 14 строке происходит открытие *.pkl файла с ранее обученной моделью, после этого данная модель может быть использована для скоринга.
Пользователь должен модифицировать данный файл со своими потребностями. Как правило, данный файл должен содержать получение переменных для скоринга (как, например, заданная в шаблоне переменная TARGET_DATE), затем открытие ранее обученной модели в формате .pkl, далее подключение к необходимой БД и загрузку данных, на которых нужно выполнить скоринг, далее непосредственно скоринг и, наконец, запись предсказанных значений в БД. Для подключения к БД потребуется использовать соответствующие учетные данные, более подробно смотрите в пунктах данного Руководства Пользователя про подключение к БД, а для передачи переменных можно посмотреть пункт «Передача переменных в Python скрипты».
Описание файла retrain.py
Файл retrain.py предназначен для переобучения модели. Также он может быть использован для первоначального обучения модели на этапе разработки модели в Jupyter. Шаблонный файл retrain.py представлен на ниже:
1 import pickle
2 import os
3
4 print("DATE_FOR_TRAIN=", os.environ.get('DATE_FOR_TRAIN'))
5 print("DATE_FOR_VALIDATION=", os.environ.get('DATE_FOR_VALIDATION'))
6
7 date_for_train = os.environ.get('DATE_FOR_TRAIN', None)
8 date_for_validation = os.environ.get('DATE_FOR_VALIDATION', None)
9
10 if (date_for_train is None) or (date_for_validation is None):
11 raise RuntimeError("Error! Не передана дата для обучения или для валидации!")
12
13
14
15 data = {"version": 1}
16
17 with open('./pkl/model.pkl', 'wb') as f:
18 pickle.dump(data, f)
В шаблоне заложено считывание из переменных окружения среды, где запускается данный файл двух дат: для обучения (DATE_FOR_TRAIN) и валидации (DATE_FOR_VALIDATION) (строки 7 и 8). Если данные даты отсутствуют в среде, где запускается данный файл, то работа скрипта будет прервана (строки 10–11). Далее в шаблоне на строке 15 обозначается “заглушка” вместо реальной модели, которая потом сохраняется как model.pkl. Пользователь должен модифицировать данный файл в соответствии со своими потребностями, общий подход, может быть, например, следующим. В начале файла в данный скрипт передаются необходимые переменные как переменные окружения среды, где запускается данный скрипт (более подробно смотрите пункт «Передача переменных в Python скрипты»). Например, это могут быть даты для обучения, даты для валидации (как в шаблоне), данные учетной записи для подключения к БД. Далее может идти блок подключения к БД, загрузка данных и непосредственно код обучения модели. Обучение модели следует логировать в MLflow (более подробно про логирование в MLflow смотрите пункт документа «Логирование эксперимента»). После того, как объект модели обучен, он должен быть сохранен в папку pkl с названием model.pkl.
Описание файла dag-batch.py
Файл dag-batch.py отвечает за создание DAG-файла для Airflow, который отвечает за скоринг моделью, то есть за запуск скрипта main.py.
Этот файл содержит следующие важные параметры:
- указываются необходимые потребные ресурсы для продуктивизированного контейнера.
- указываются какие секреты Кубернетес будет примонтированы к продуктивизированному контейнеру. В шаблонном файле реализовано примонтирование секрета с keytab-файлом для аутентификации в Hive через kerberos и секрет tech-ora-creds с данными технической учетной записи для подключения к Oracle.
- задается расписание запуска модели (schedule).
- задаются переменные окружения, которые будут переданы в скрипт main.py, запускаемый в продуктивизированном контейнере.
Рассмотрим шаблон dag-batch.py ниже:
1 from airflow import DAG
2 from datetime import datetime, timedelta, date
3 from airflow.contrib.operators.kubernetes_pod_operator import KubernetesPodOperator
4 from kubernetes.client import models as k8s
5 import pytz
6 # Connection via tech-creds
7 ora_creds_vars = [k8s.V1EnvFromSource(secret_ref=k8s.V1SecretEnvSource(name='tech-ora-creds'))]
8
9
10 target_date = date.today().strftime('%d.%m.%Y')
11
12 default_args = {
13 'owner': 'airflow',
14 'depends_on_past': False,
15 'start_date': datetime(2020, 11, 1, tzinfo=pytz.timezone('Europe/Moscow')),
16 'email': ['${TP_ML_USER}@glowbyteconsulting.com'],
17 'email_on_failure': False,
18 'email_on_retry': False,
19 'retries': 1,
20 'retry_delay': timedelta(minutes=5)
21 }
22
23 dag = DAG(
24 '${CI_PROJECT_NAME}',
25 default_args=default_args,
26 # schedule_interval='*/15 * * * *',
27 schedule_interval = timedelta(hours=12),
28 catchup=False,
29 params = {'target_date':target_date}
30 )
31
32 container_resources=k8s.V1ResourceRequirements(
33 requests={'cpu': '1', 'memory': '1Gi',
'nvidia.com/gpu': '0'},
34 limits={'cpu': '2', 'memory': '4Gi',
'nvidia.com/gpu': '0'},
35 )
36
37 passing = KubernetesPodOperator(
38 namespace='${NS}',
39 image="${DOCKER_REGISTRY}/${NEXUS_SPACE}/${CI_PROJECT_NAME}:${TAG}.${CI_PIPELINE_ID}",
40 name="${CI_PROJECT_NAME}_${CI_PIPELINE_ID}",
41 task_id="run_model",
42 volume_mounts=[volume_mount],
43 volumes=[volume],
44 get_logs=True,
45 dag=dag,
46 resources=container_resources,
47 is_delete_operator_pod=True,
48 env_from=ora_creds_vars,
49 env_vars= [k8s.V1EnvVar(name='TARGET_DATE', value="{{ params.target_date }}")]
50 )
51
52 passing
23 dag = DAG(
24 'testproject',
25 default_args=default_args,
26 # schedule_interval='*/15 * * * *',
27 schedule_interval = timedelta(hours=12),
28 catchup=False,
29 params = {'target_date':target_date}
30 )
В 7 строке из секрета с именем tech-ora-creds забираются переменные окружения для технической учетной записи для Oracle, имена этих переменных перечислены в Приложении Б «Список имен переменных окружения и их значения для секрета tech-ora-creds». Далее данные переменные окружения передаются в контейнер с моделью, это указано на строке 48.
В 10 строке обозначается переменная target_date, которой присваивается значение текущего дня.
В 12–21 строках указываются default аргументы для объекта DAG, следует обратить внимание на параметр retries и retray_delay. В случае, если в Airflow данный DAG-файл при попытке запуска получил ошибку, то данные параметры отвечают за число повторных запусков и за задержку между ними. Соответственно, при шаблонных значениях, в случае ошибки при старте, данный DAG-файл попробует перезапуститься еще 1 раз через 5 минут после первого запуска.
В 23–30 строках обозначается объект DAG, здесь стоит обратить внимание на параметр schedule_interval, отвечающий за запуск DAG-файла по расписанию. Допускается несколько форматов задания расписания, например, можно реализовывать расписание с помощью cron-шаблона (для удобства использования данного формата можно сначала отладить нужное расписание с помощью сервиса https://crontab.guru/, а затем вставить его как значение расписания. Либо можно задавать расписание с помощь объекта timedelta из библиотеки datetime. Именно такой метод расписания указан в шаблонном файле, таким образом следующий запуск данного DAG-файла будет спустя 12 часов после первого запуска. Третий способ задания расписания запуска — это с помощью конструкции Timetable Airflow, более подробную информацию по такому способу задания расписания можно посмотреть на официальном сайте Airflow). Также в 29 строке указывается переменная params, в которую передается словарь (dict), содержащий название и значение переменной (в случае данного шаблона - target_date).
В строках 32–35 задаются параметры ресурсов (CPU, RAM, GPU) для продуктивизированного контейнера, то есть контейнера, в котором будет запускаться скрипт main.py. Более подробно про выбор ресурсов смотрите в разделе “Выбор ресурсов для продуктивизированного контейнера“.
В 37–50 строках обозначается объект KubernetesPodOperator, с помощью которого средствами Airflow будет запускаться контейнер с продуктивизированной моделью. Важно обратить внимание на строку 48, где происходит передача переменных окружения из секрета с технической учетной записи для Oracle и на строку 49, где также передается переменная окружения, но не из секрета, а обозначенная в данном файле на строке 10 target_date. Параметр name внутри конструкции на данной строке обозначает имя, под которым данная переменная будет передана в контейнер, то есть это имя переменной окружения, которая будет доступна при запуске скрипта main.py в случае обращения к ней с помощью метода os.environ.get(‘TARGET_DATE’). Параметр value содержит специальную конструкцию, обернутую в двойные фигурные кавычки, которая позволяет передать переменной TARGET_DATE значение, присвоенное на строке 10. Кроме того, если данный DAG-файл в Airflow будет запущен с опцией “run DAG w config”, где Пользователем будет указано иное значение target_date, то в контейнер со скриптом main.py будет переданное новое значение, а не то, что было присвоено на строке 10.
Пользователь Системы должен модифицировать данный файл под свои требования при разработке модели, например, указывать нужное расписание и передавать нужные переменные с необходимыми значениями в контейнер.
Описание файла dag-retrain.py
Файл dag-retrain.py отвечает за создание DAG-файла для Airflow, который отвечает за переобучение модели, то есть за запуск скрипта retrain.py.
Этот файл содержит следующие важные параметры:
- указываются необходимые потребные ресурсы для продуктивизированного контейнера.
- указываются даты для обучения (тренинга) и валидации модели.
- указываются какие секреты Kubernetes будет примонтированы к продуктивизированному контейнеру с переобучением. В шаблонном файле реализовано примонтирование секрета с keytab-файлом для аутентификации в Hive через kerberos и секрет tech-ora-creds с данными технической учетной записи для подключения к Oracle.
- задается расписание запуска переобучения модели (schedule).
- задаются переменные окружения, которые будут переданы в скрипт retrain.py, запускаемый в продуктивизированном контейнере.
Рассмотрим шаблон dag-retrain.py ниже:
1 from airflow import DAG
2 from datetime import datetime, timedelta, date
3 from airflow.contrib.operators.kubernetes_pod_operator import KubernetesPodOperator
4 from kubernetes.client import models as k8s
5 import pytz
6
7 #Для переобучения модели нужно указать дату для обучения модели и дату для валидации.
8 #Их можно задать как таймдельту от текущего дня, либо передавать это параметрами конфига,
9 #с которым запускается dag-файл.
10 date_for_train = (date.today() - timedelta(weeks=4)).strftime('%d.%m.%Y')
11 date_for_validation = (date.today() - timedelta(weeks=2)).strftime('%d.%m.%Y')
12
13
14 volumes = [
15 k8s.V1Volume(
16 name='retrain-volume',
17 persistent_volume_claim=k8s.V1PersistentVolumeClaimVolumeSource(claim_name='${CI_PIPELINE_ID}-retrain-tmp-dir'),)
18 ]
19
20 volume_mounts =
21 k8s.V1VolumeMount(mount_path='/app/pkl', name='retrain-volume')
22 ]
23
24 # Connection via tech-creds
25 ora_creds_vars = [k8s.V1EnvFromSource(secret_ref=k8s.V1SecretEnvSource(name='tech-ora-creds'))]
26
27 default_args = {
28 'owner': 'airflow',
29 'depends_on_past': False,
30 'start_date': datetime(2020, 11, 1, tzinfo=pytz.timezone('Europe/Moscow')),
31 'email': ['${TP_ML_USER}@glowbyteconsulting.com'],
32 'email_on_failure': False,
33 'email_on_retry': False,
34 'retries': 1,
35 'retry_delay': timedelta(minutes=5)
36 }
37
38 env_vars = [
39 k8s.V1EnvVar(name='CI_SERVER_HOST', value='$CI_SERVER_HOST'),
40 k8s.V1EnvVar(name='GIT_GROUP', value='$GIT_GROUP'),
41 k8s.V1EnvVar(name='CI_PROJECT_NAME', value='$CI_PROJECT_NAME'),
42 k8s.V1EnvVar(name='CI_PIPELINE_ID', value='$CI_PIPELINE_ID'),
43 k8s.V1EnvVar(name='S3_BUCKET', value='$S3_BUCKET'),
44 k8s.V1EnvVar(name='S3_ENDPOINTURL', value='$S3_ENDPOINTURL'),
45 k8s.V1EnvVar(name='NS', value='$NS')
46 ]
47
48 env_from_list = [k8s.V1EnvFromSource(secret_ref=k8s.V1SecretEnvSource(name='retrain-creds'))]
49
50 dag = DAG(
51 '${CI_PROJECT_NAME}_retrain',
52 default_args=default_args,
53 # schedule_interval='*/15 * * * *',
54 schedule_interval = timedelta(minutes=60),
55 catchup=False,
56 params = {'date_for_train':date_for_train, 'date_for_validation':date_for_validation}
57 )
58
59 container_resources=k8s.V1ResourceRequirements(
60 requests={'cpu': '1', 'memory': '1Gi'},
61 limits={'cpu': '2', 'memory': '4Gi'},
62 )
63
64 pvc_create = KubernetesPodOperator(
65 namespace='${NS}',
66 image="${DOCKER_REGISTRY}/${NEXUS_SPACE}/${TECH_IMAGE}",
67 name="pvc-create-${CI_PROJECT_NAME}-${CI_PIPELINE_ID}",
68 service_account_name="retrain-sa",
69 task_id="pvc_create",
70 cmds=["bash"],
71 arguments=["sh/gen_pvc.sh"],
72 env_vars=env_vars,
73 env_from=env_from_list,
74 get_logs=True,
75 dag=dag,
76 is_delete_operator_pod=True,
77 )
78
79 # Retrain
80
81 retrain = KubernetesPodOperator(
82 namespace='${NS}',
83 image="${DOCKER_REGISTRY}/${NEXUS_SPACE}/${CI_PROJECT_NAME}:${TAG}.${CI_PIPELINE_ID}",
84 name="retrain-${CI_PROJECT_NAME}-${CI_PIPELINE_ID}",
85 task_id="retrain_model",
86 volume_mounts=volume_mounts,
87 volumes=volumes,
88 get_logs=True,
89 dag=dag,
90 resources=container_resources,
91 env_from=ora_creds_vars+env_from_list,
92 env_vars={"DATE_FOR_TRAIN": "{{ params.date_for_train }}",
93 "DATE_FOR_VALIDATION": "{{ params.date_for_validation }}"},
94 is_delete_operator_pod=True,
95 )
96
97 push_pkl = KubernetesPodOperator(
98 namespace='${NS}',
99 image="${DOCKER_REGISTRY}/${NEXUS_SPACE}/${TECH_IMAGE}",
100 name="push-pkl-${CI_PROJECT_NAME}-${CI_PIPELINE_ID}",
101 task_id="push_pkl",
102 cmds=["bash"],
103 arguments=["sh/git_dvc.sh"],
104 # arguments=["sh/git_dvc_f.sh"],
105 env_vars=env_vars,
106 env_from=env_from_list,
107 volume_mounts=volume_mounts,
108 volumes=volumes,
109 get_logs=True,
110 dag=dag,
111 is_delete_operator_pod=True,
112 )
113
114 del_pvc = KubernetesPodOperator(
115 namespace='${NS}',
116 image="${DOCKER_REGISTRY}/${NEXUS_SPACE}/${TECH_IMAGE}",
117 name="del-pvc-${CI_PROJECT_NAME}-${CI_PIPELINE_ID}",
118 service_account_name="retrain-sa",
119 task_id="del_pvc",
120 cmds=["bash"],
121 arguments=["sh/del_pvc.sh"],
122 env_vars=env_vars,
123 env_from=env_from_list,
124 get_logs=True,
125 dag=dag,
126 is_delete_operator_pod=True,
127 )
128
129 retrain.set_upstream(pvc_create)
130 push_pkl.set_upstream(retrain)
131 del_pvc.set_upstream(push_pkl)
Рассмотрим основные функции кода в данном файле.
На 10–11 строках обозначаются переменные date_for_train и date_for_validation, отвечающие за дату для обучения и для валидации, необходимые для скрипта переобучения. Их значения берутся как сегодняшняя дата минус 4 недели и минус 2 недели соответственно.
Пользователь при разработке реальной модели должен изменить данные даты по своему усмотрению.
На 25 строке обозначается переменная ora_creds_vars, значением которой является список переменных окружения из технической учетной записи для Oracle, список и значения данных переменных можно найти в Приложении Б «Список имен переменных окружения и их значения для секрета tech-ora-creds».
На 27–36 строках указываются default аргументы для объекта DAG, следует обратить внимание на параметр retries и retray_delay. В случае, если в Airflow данный DAG-файл при попытке запуска получил ошибку, то данные параметры отвечают за число повторных запусков и за задержку между ними. Соответственно, при шаблонных значениях, в случае ошибки при старте, данный DAG-файл попробует перезапуститься еще 1 раз через 5 минут после первого запуска.
Строки 38–48 задают необходимые технические переменные окружения.
На 50–57 строках обозначается объект DAG, здесь стоит обратить внимание на параметр schedule_interval, отвечающий за запуск DAG-файла по расписанию. Допускается несколько форматов задания расписания, например, можно реализовывать расписание с помощью cron-шаблона (для удобства использования данного формата можно сначала отладить нужное расписание с помощью сервиса https://crontab.guru/, а затем вставить его как значение расписания. Либо можно задавать расписание с помощь объекта timedelta из библиотеки datetime). Именно такой метод расписания указан в шаблонном файле, таким образом следующий запуск данного DAG-файла будет спустя 12 часов после первого запуска. Третий способ задания расписания запуска — это с помощью конструкции Timetable Airflow, более подробную информацию по такому способу задания расписания можно посмотреть на официальном сайте Airflow. Также на 56 строке указывается переменная params, в которую передается словарь (dict), содержащий названия и значения переменных.
На строках 59–62 задаются ресурсы контейнера, в котором будет выполняться переобучение модели, то есть ресурсы контейнера, где будет запускаться скрипт retrain.py. Более подробно про выбор ресурсов контейнера смотрите в разделе “Выбор ресурсов для продуктивизированного контейнера“.
Далее обозначаются четыре объекта KubernetesPodOperator, первый, третий и четвертый являются техническими, поэтому их описание можно пропустить. Более подробно рассмотрим второй KubernetesPodOperator (строки 81–95). Важно обратить внимание на строки 91 и 92, на которых передаются в контейнер, где запускается скрипт переобучения retrain.py, заданные ранее из секретов или в параметрах (params) переменные окружения.
Передача переменных в python скрипты
Для эффективной работы в Системе Пользователь должен понимать как реализована передача переменных для python скриптов, запускаемых в контейнере.
Предположим, что разработана модель, имеется файл main.py, в котором запускается обученная модель (файл model.pkl), далее в этом скрипте необходимо обратиться в БД, чтобы получить данные для скоринга. В этом случае дата (target_date), на которую нужно получить, является переменной, которую нужно передать в скрпит main.py, который будет в контейнере по расписанию, указанному в файле dag-batch.py. То есть, когда произойдет активация DAG-файла в Airflow, то будет запущен контейнер, в котором фактически будет выполнена команда python3 main.py. Рассмотрим механизм передачи переменной target_date внутрь скрипта main.py. Значение target_date должно быть указано в файле dag-batch.py, например, так:
Далее в файле dag-batch.py эта переменная должна быть указана в params объекта dag:dag = DAG(
'${CI_PROJECT_NAME}',
default_args=default_args,
# schedule_interval='*/15 * * * *',
schedule_interval = timedelta(hours=12),
catchup=False,
params = {'target_date':target_date}
)
Здесь в params передается объект типа словарь (dict), где в качестве ключа (key) выступает имя переменной, а в качестве значения (value) само значение переменной. Наконец, в этом же файле dag-batch.py при создании объекта KubernetesPodOperator указать в параметрах env_vars (пример ниже).
passing = KubernetesPodOperator(
namespace='${NS}',
image="${DOCKER_REGISTRY}/${NEXUS_SPACE}/${CI_PROJECT_NAME}:${TAG}.${CI_PIPELINE_ID}",
name="${CI_PROJECT_NAME}_${CI_PIPELINE_ID}",
task_id="run_model",
volume_mounts=[volume_mount],
volumes=[volume],
get_logs=True,
dag=dag,
is_delete_operator_pod=True,
env_from=ora_creds_vars,
env_vars= [k8s.V1EnvVar(name='TARGET_DATE', value="{{ params.target_date }}")]
)
Рассмотрим более подробно строку:
В качестве значения env_vars присваивается список, в данном примере содержащий единственный элемент. Этот элемент является объектомk8s.V1EnvVar , с помощью которого можно задать переменную окружения, которая будет доступна в контейнере с python скриптом. У объекта k8s.V1EnvVar необходимо задать параметр name, который задает имя данной переменной окружения и параметр value , который задает значение данной переменной окружения. Значение параметра value задается с помощью специальной конструкции в двойных фигурных скобках, где само значение берется из params объекта dag, рассмотренного выше.
Теперь при запуске данного DAG’a в Airflow внутри контейнера, где будет запущен скрипт main.py будет доступная переменная окружения TARGET_DATE, имеющая значение сегодняшней даты. Для того, чтобы внутри скрипта main.py обратиться к данной переменной необходимо выполнить следующий код:
Следует отметить, что Пользователь на этапе разработке модели должен продумывать какие переменные нужно передавать для разрабатываемой им модели и модифицировать файл main.py и dag-batch.py под свои потребности.Полностью аналогичный механизм передачи переменных реализован и для переобучения модели (файл retrain.py и dag-retrain.py), только для файла dag-retrain.py следует обратить внимание, что передача переменных окружения проводится во втором объекте KubernetesPodOperator (всего в файле dag-retrain.py четыре объекта KubernetesPodOperator).
В заключение данного раздела следует отметить следующее. На этапе разработки модели (напомним, разработка модели идет в контейнере для разработки, то есть в продакшине модель работает в “продуктовом” контейнере, а разрабатывается в контейнере для разработки) важно отладить работу скриптов main.py и retrain.py. При этом, если скрипты main.py и retrain.py содержат обращения к переменным окружения с помощью os.environ.get, то необходимо предварительно обозначить эти переменные как переменные окружения в терминале, из которого запускаются данные скрипты.
Например, если требуется отладить внутри контейнера скрипт main.py, который обращается к переменной окружения os.environ.get(‘TARGET_DATE’), то в Jupyter надо открыть терминал (более подробно про работу с терминалом смотрите в разделе «Работа с терминалом»), в нем указать команду export TARGET_DATE=”01.01.2022”, далее в данном же терминале перейти в папку с проектом и запускать скрипт main.py. В этом случае после строки в main.py target_date = os.environ.get('TARGET_DATE') значением переменной target_date будет строка ”01.01.2022”.
Похожий прием с экспортом переменных окружения перед запуском скриптов python в терминале может быть использован для обозначения переменных, связанных с учетными записями для доступа к БД, которые необходимы при отладке.
Выбор ресурсов для продуктивизированного контейнера
При разработке batch модели в файлах dag-batch.py и dag-retrain.py необходимо указать ресурсы контейнера, в котором будет производиться скоринг моделью (запуск файла main.py) и переобучение модели (запуск файла retrain.py). Под ресурсами здесь понимается количество ядер CPU и объем RAM.
В параметрах контейнера могут быть указаны два параметра, задающие параметры ресурсов, с которыми запустить контейнер:
- limits - верхняя граница ресурсов, если работа контейнера начнет потреблять больше ресурсов, чем данное значение, то контейнер будет остановлен средствами Kubernetes.
- requests - нижняя граница ресурсов, необходимых для работы контейнера. Например, если мы знаем, что для работы контейнера с моделью, которая делает скоринг нужно не менее 30гб RAM, то должны указать это в requests. В этом случае, когда данный DAG-файл будет активирован в Airflow, то Kubernetes будет искать ноду кластера, на которой имеется указанное в requests количество ресурсов. Если такой ноды найдено не будет, то Kubernetes не сможет запустить контейнер и в логах Airflow появиться ошибка о том, что pod с моделью не смог запуститься. В этом случае следует обратиться к Администратору системы. Напомним, синтаксис задания ресурсов должен быть следующий: В этом примере минимальный набор ресурсов для контейнера будет 1 CPU, 1Гб оперативной памяти и ни одного GPU, а верхний лимит, при выходе за который Kubernetes “убьет”, контейнер составляет 2 CPU и 4Гб оперативной памяти. В приведенном примере количество GPU указано равным нулю, данное значение берется при создании Проекта модели в creat_project.ipynb на этапе вопроса про необходимость использования библиотеки CUDA. То есть, если на том этапе указано значение, например, 1, то оно будет подставлено в файлы dag-batch.py и dag-retrain.py. Обратите внимание, если для работы скоринга модели и переобучения модели требуется использование GPU, то необходимо указывать количество требуемых ядер GPU.
При разработке модели возникает вопрос о том, какие же границы ресурсов выбрать. Для определения параметров контейнера с моделью, то есть контейнера для скоринга моделью, а не контейнера переобучения, на этапе разработки модели в Jupyter запустить скрипт main.py и посмотреть сколько памяти потребляется при работе скрипта, рисунок Ресурсы Jupyter.
Взяв данное максимальное значение потребляемой памяти во время работы скрипта, можно увеличить его на 10–20% и использовать это число как в requests. Число CPU для requests можно взять равное тому значению, которое было выбрано при старте контейнера с Jupyter. Далее верхнюю границу ресурсов (limits) можно выбрать такое же как requests. Для контейнера с переобучение модели выбор ресурсов может быть выполнен по аналогичной схеме, только наблюдать за потребляемой памятью нужно во время запуска скрипта retrain.py.
Для онлайн моделей значения необходимых ресурсов задается в файле online/deployment.yaml на строке “resources”. Здесь также нужно задать количество cpu и memory для полей requests и limits. Если для работы онлайн модели требуется GPU, то необходимо ниже строки “memory” добавить строку nvidia.com/gpu: "1", где вместо 1 может быть необходимое число ядер GPU. Пример файла deployment с GPU можно посмотреть в ветке online проекта gbc/hlkupliftmodel.
Установка дополнительных библиотек
Образ, который выбран и запущен в начале работы, уже содержит определенный набор библиотек и фреймворков списком которых можно запросить у Администратора. У Пользователя существует возможность установить в рамках сервера дополнительные библиотеки.
Для установки библиотек Python можно использовать команду pip install.
Для вызова pip нужно сначала перейти в режим терминала (см. раздел Работа с терминалом) или запустить эту программу непосредственно из блокнота (см. соответствующий раздел документации IPython).
Следует отметить, что установленные Пользователем библиотеки сохраняются в персистивное хранилище данного Пользователя, поэтому будут доступны после удаления (остановки), текущего Jupyter сервера, иными словами, достаточно один раз установить недостающую библиотеку, а при последующих запусках JupyterLab данная библиотека будет уже доступна, однако, чтобы данная свежеустановленна библиотека была доступна при последующей продуктивизации модели ее название следует добавить в файл requirements.txt.
Если потребуется добавить библиотеку в базовый стек (базовый образ), чтобы она была доступна всем пользователям системы, то обратитесь к Администратору.
Завершение работы с JupyterLab сервером
В случае если требуется завершить текущий сеанс работы над проектом модели, необходимо сохранить внесенные в код изменения и остановить работу контейнера, чтобы освободить ресурсы системы. Для этого:
- Находясь внутри окна блокнота, следует нажать на меню “File” и далее “Save notebook” в левом верхнем углу;
- Перейдите в раздел “File” основного меню и выберите пункт “Hub Control Panel”
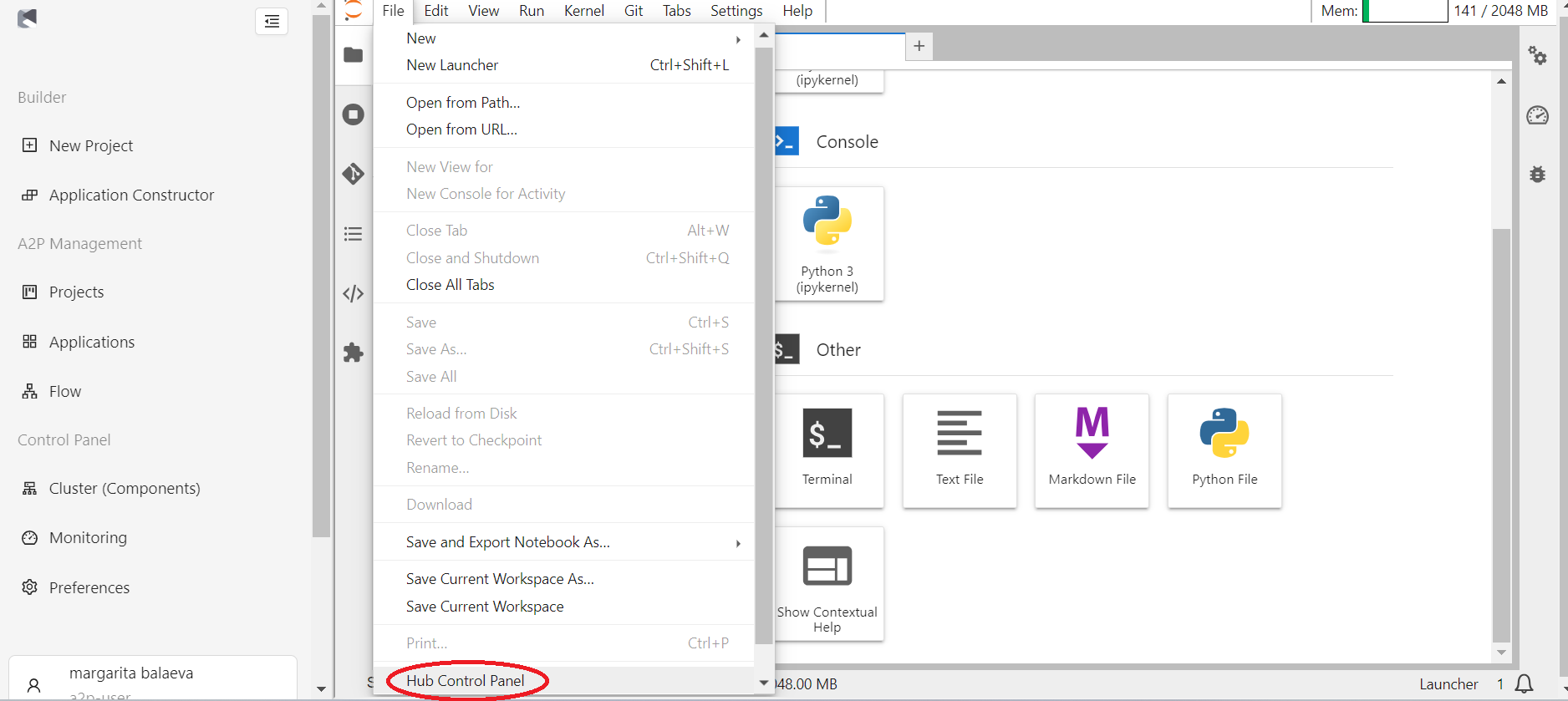
В открывшемся окне нажмите на кнопку “Stop My Server”.
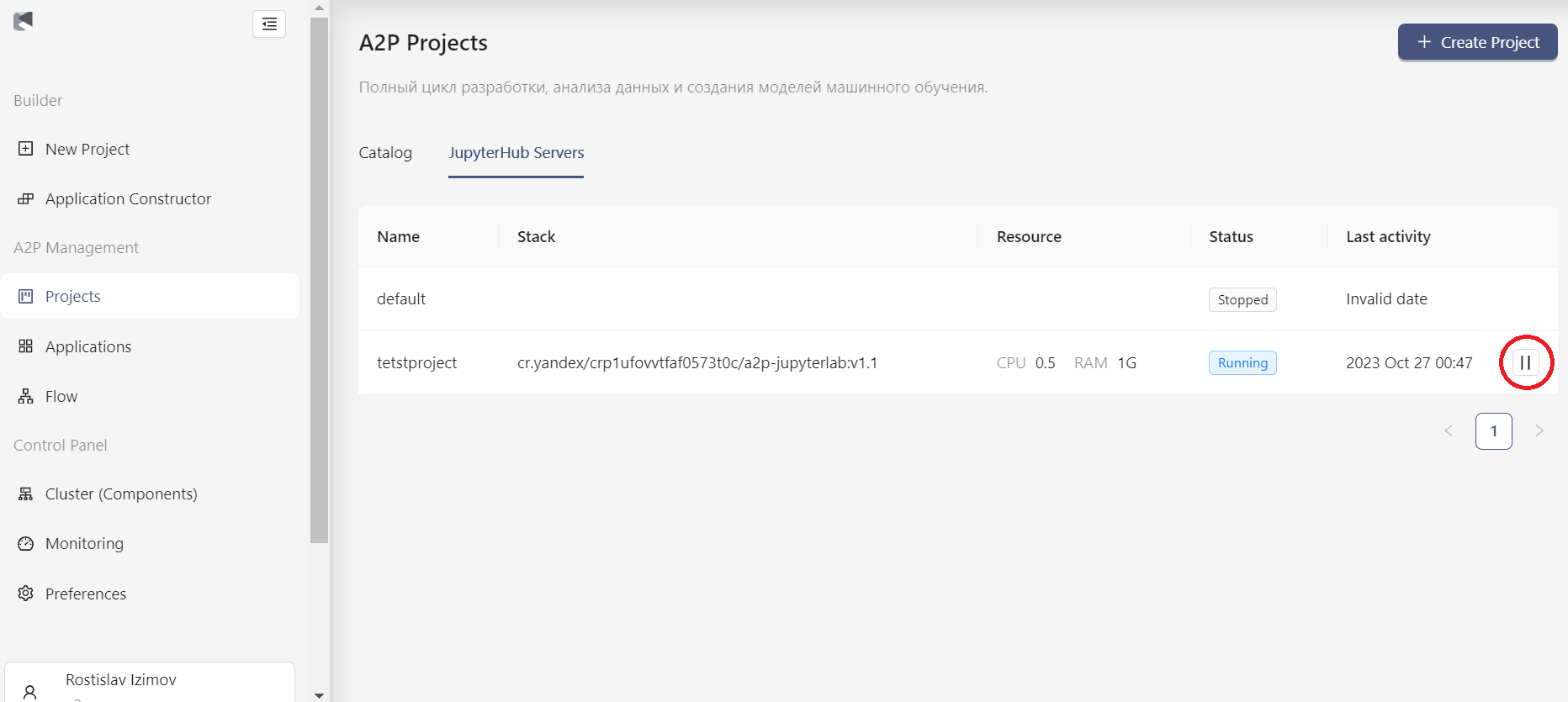
Также завершить работу с сервером можно из модуля A2P. Для этого необходимо перейти в "Projects", далее в "JupyterHub Servers", выбрать знак паузы у интересующего контейнера (см. рисунок).